
 설문, 신뢰도(Cronbach’s α) 제대로 보는 법")



:")
, 왜 쓰고 어떻게 해석해야 할까?")


데이터 입력도 했고, 코딩도 끝났는데
막상 분석 결과가 이상하게 나오는 경우가 있습니다.
평균이 이상하게 튀거나,
신뢰도 값이 낮게 나오거나,
회귀분석 결과가 설명이 안 되는 상황.
이럴 때 원인은 대부분 결측값과 이상치입니다.
분석 전에 이 두 가지만 정리해도,
결과 해석이 훨씬 자연스러워집니다.
1) 결측값(Missing Values) 먼저 확인하기
엑셀에서 넘어온 데이터에는 생각보다 결측이 많습니다.
- 응답자가 문항을 건너뜀
- ‘-’, ‘.’, 공백으로 입력됨
- 특정 문항에만 유독 응답이 비어 있음
이걸 모른 채 평균, 상관, 회귀를 돌리면
표본 수(N)가 분석마다 달라집니다.
확인 방법
Analyze → Descriptive Statistics → Frequencies
- 각 문항의 Missing 개수 확인
- 유독 많이 비어 있는 문항 찾기
2) 결측값 처리 방법 결정하기
결측을 어떻게 처리할지는 연구자 판단입니다.
| 방법 | 언제 사용? |
|---|---|
| 해당 케이스 삭제 | 결측이 소수일 때 |
| 평균값 대체 | 리커트 척도, 결측이 약간 있을 때 |
| 특정 값으로 지정 | 설문 설계상 의도된 경우 |
중요한 건, 모르고 분석하지 않는 것입니다.
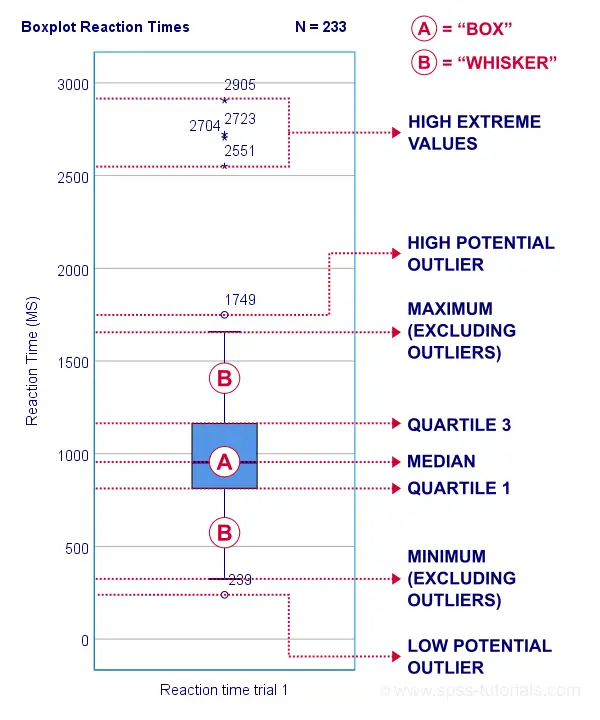
3) 이상치(Outlier) 확인 — Boxplot 활용
평균을 심하게 왜곡하는 값들이 있습니다.
예를 들어, 모두 3~5점인데
혼자 1점만 반복하는 응답자.
확인 방법
Graphs → Boxplot
박스플롯을 보면 점으로 튀는 값들이 보입니다.
이걸 무조건 삭제하는 게 아니라,
왜 이런 응답이 나왔는지 먼저 확인
불성실 응답인지, 실제 특이 케이스인지 판단해야 합니다.
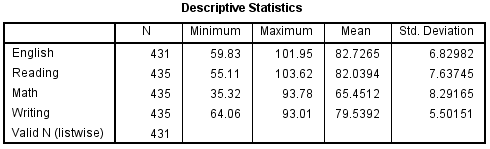
4) 기술통계로 한 번 더 점검
Analyze → Descriptive → Descriptives
- 평균(Mean)
- 표준편차(Standard Deviation)
- 최소/최대값(Min/Max)
여기서 범위를 벗어난 값이 있는지 확인합니다.
리커트 5점인데 최대값이 9?
→ 데이터 입력 오류입니다.
5) 필요한 경우, 특정 케이스만 제외하기
전체를 지우는 게 아니라,
문제가 되는 응답자만 제외할 수도 있습니다.
Data → Select Cases
조건을 설정해 특정 케이스만 분석에서 제외 가능합니다.
이 과정을 거치면 달라지는 점
- 평균이 정상 범위로 돌아옵니다.
- 신뢰도 분석 값이 안정됩니다.
- 회귀/상관 결과 해석이 자연스러워집니다.
- 표본 수(N)가 일관되게 유지됩니다.
SPSS 결과가 이상했던 이유는
통계를 못해서가 아니라,
정리되지 않은 데이터를 그대로 분석했기 때문입니다.

분석 전 체크리스트
- Frequencies로 결측 확인했는가?
- 결측 처리 방법을 결정했는가?
- Boxplot으로 이상치를 확인했는가?
- Descriptives로 범위를 점검했는가?
- 필요한 케이스만 선택적으로 제외했는가?
이 과정을 한 번만 해도, SPSS 결과는 놀랄 만큼 ‘설명 가능한 결과’로 바뀝니다.



